
Lecture 7
Contents
- Introduction
- Edge AI
- Key Differences Between Edge AI and Regular AI
- Benefits of inference at the Edge
- Bandwidth, Latency, Economics, Reliability and Privacy (BLERP):
- Components of Edge Computing
- Edge Computing Hardware
- Types of Edge devices:
- Microcontrollers - Low-End Variants
- Microcontrollers - High-End Variants
- Digital Signal Processors (DSPs)
- Heterogeneous Compute
- System-on-Chip (SoC) Devices
- Deep Learning Accelerators (NPUs)
- FPGAs and ASICs
- Development Boards & Production Ready Devices
- Edge Servers/Gateway
- Multi-Device Architectures
- Edge Software:
- Containers and Microservices (Critical for Edge AI)
- Implementation:
Introduction
Definition
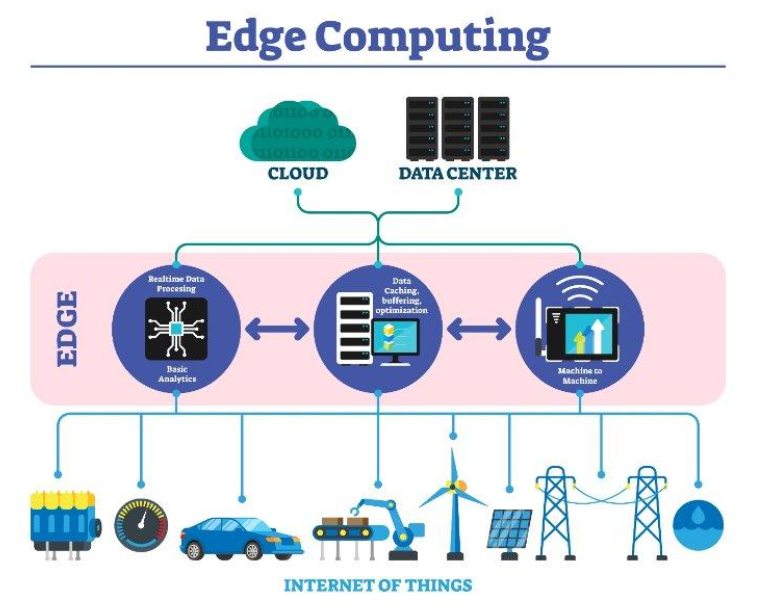
Edge computing processes data directly on a device or in close proximity to it, rather than sending it all to a central cloud network.
This approach is essential for handling the massive volume of data generated by modern devices, as it reduces the burden on the cloud and offers several key advantages. By performing computations at the edge, this method enables low latency, faster response times, and privacy by processing data closer to its source.
This approach is particularly well-suited for real-time applications, as it significantly reduces the need to send data over a network, leading to faster response times and lower latency. It's especially beneficial for a portion of the Internet of Things (IoT), where privacy, rapid responses, and big data volumes can be a major challenge for traditional cloud networks.
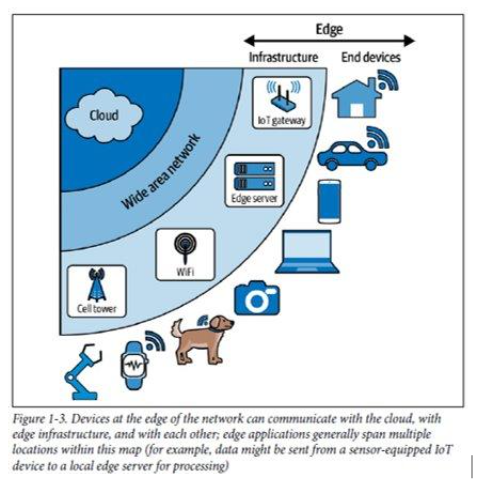
The edge isn’t a single place, it’s more like a broad region. Devices at the edge of the network can communicate with each other, and they can communicate with remote servers, too. There are even servers that live at the edge of the network
Edge AI
Definition
Edge AI is, unsurprisingly, the combination of edge devices and artificial intelligence. Edge devices are the embedded systems that provide the link between our digital and physical worlds. They typically feature sensors that feed them information about the environment they are close to.
This gives them access to a metaphorical fire hose of high-frequency data. We’re often told that data is the lifeblood of our modern economy, flowing through out our infrastructure and enabling organizations to function. That’s definitely true but all data is not created equally. The data obtained from sensors tends to have a very high volume but a relatively low informational content.
-
Imagine the accelerometer-based wristband sensor. The accelerometer is capable of taking a reading many hundreds of times per second. Each individual reading tells us very little about the activity currently taking place—it’s only in aggregate, over thousands of readings, that we can begin to understand what is going on.
-
Typically, IoT devices have been viewed as simple nodes that collect data from sensors and then transmit it to a central location for processing. The problem with this approach is that sending such large volumes of low-value information is extraordinarily costly. Not only is connectivity expensive, but transmitting data uses a ton of energy—which is a big problem for battery-powered IoT devices. Because of this problem, the vast majority of data collected by IoT sensors has usually been discarded. We’re collecting a ton of sensor data, but we’re unable to do anything with it.
-
Edge AI is the solution to this problem. Instead of having to send data off to some distant location for processing, what if we do it directly on-device, where the data is being generated? Now, instead of relying on a central server, we can make decisions locally without provisions of the connectivity. If we still want to report information back to upstream servers, or the cloud, we can transmit just the important information instead of having to send every single sensor reading. That should save a lot of cost and energy. There are many different ways to deploy intelligence to the edge.
Figure shows the continuum from cloud AI to fully on-device intelligence. As we’ll see later, edge AI can be spread across entire distributed computing architectures—including some nodes at the very edge, and others in local gateways or the cloud.
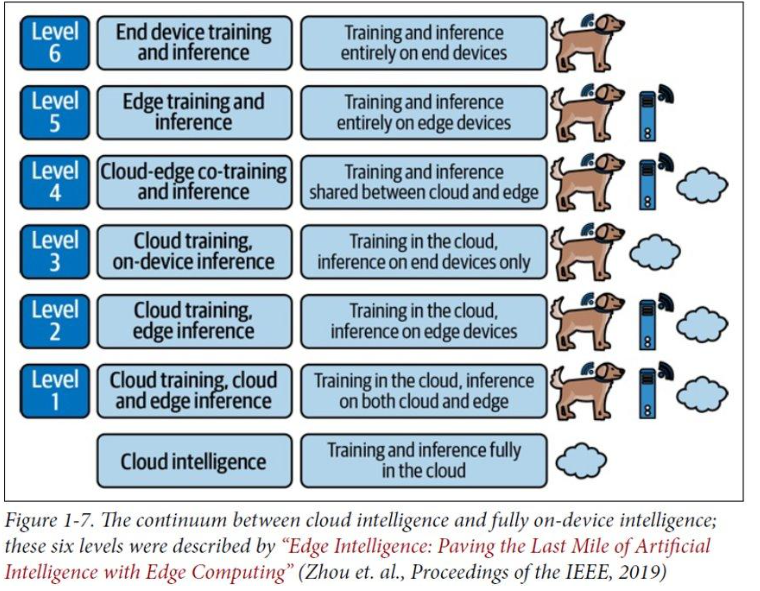
As we’ve seen, artificial intelligence can mean many different things. It can be super simple: a touch of human insight encoded in a little simple conditional logic. It can also be super sophisticated, based on the latest developments in deep learning. Edge AI is exactly the same. At its most basic, edge AI is about making some decisions on the edge of the network, close to where the data is made. But it can also take advantage of some really cool stuff.
Key Differences Between Edge AI and Regular AI
Training vs. Inference
-
Training on the edge is rare. Edge AI is almost exclusively focused on inference (making predictions). The resource-intensive training of models is typically done offline on powerful servers and then deployed to the edge.
-
Data Focus: While traditional AI often works with structured, tabular data, Edge AI specializes in making sense of continuous, high-frequency, and messy sensor data from the physical world.
-
Model Size: Edge AI models must be very small to fit on resource-constrained devices with limited memory and processing power, often requiring a trade-off between model size and accuracy.
-
Feedback & Updates: The ability to continuously learn and improve from new data is limited in Edge AI due to connectivity constraints. Gathering real-world performance feedback and pushing model updates can be a significant challenge.
-
Hardware Diversity: Unlike the relatively uniform hardware in cloud computing (mostly x86 CPUs and GPUs), the Edge AI ecosystem involves a wide variety of hardware such as:
- System-on-chip (SoC) devices running embedded Linux
- General-purpose accelerators based on GPU technology
- Field programmable gate arrays (FPGAs)
- Fixed architecture accelerators that run a single model architecture blazing fast
Benefits of inference at the Edge
-
Handling High-Volume, Low-Value Data: Edge devices, like sensors, collect a huge volume of data at a very high frequency. For example, an accelerometer might take hundreds of readings per second. However, each individual reading contains very little useful information on its own; meaning must be derived from thousands of readings combined.
-
Overcoming Transmission Costs and Bottlenecks: The traditional model of sending all raw, high-volume sensor data to a central cloud for processing is extremely expensive and inefficient. Transmitting this data consumes a significant amount of energy, which is a major issue for battery-powered IoT devices, and clogs network bandwidth. As a result, much of this valuable sensor data is often discarded without being analyzed.
-
Enabling On-Device Processing: Edge AI provides a solution by moving the processing of data directly onto the device where it is generated. Instead of transmitting every sensor reading, the device can analyze the data locally and make real-time decisions without needing a connection to the cloud.
-
Reducing Cost and Energy Use: By only sending aggregated or important information back to central servers, such as an alert or a summarized trend, Edge AI drastically cuts down on the amount of data transmitted. This significantly reduces both communication costs and energy consumption. The intelligence can range from simple conditional logic to sophisticated deep learning models, making it a flexible solution for a wide range of applications.
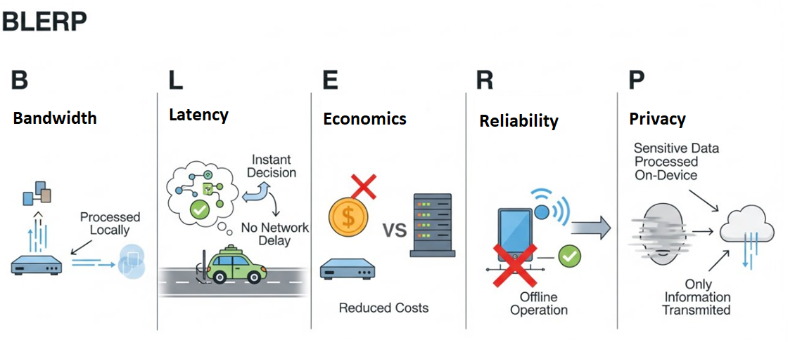
Bandwidth, Latency, Economics, Reliability and Privacy (BLERP):
Jeff Bier, founder of the Edge AI and Vision Alliance, created this excellent tool for expressing the benefits of edge AI. The primary goal of Edge AI is often not to achieve perfect performance but to be good enough to provide significant value. The benefits of local processing (BLERP) often outweigh a slight reduction in accuracy. Let’s discuss these one by one.
- Bandwidth: Edge AI solves the problem of transmitting massive amounts of low-value sensor data. Instead of sending everything to the cloud and discarding most of it, Edge AI processes the data locally. This allows devices to send only essential information, like an alert about a potential machine failure, saving energy and overcoming bandwidth limitations.
- Latency: Transmitting data to a distant server takes time. In applications where a fast response is critical, like in self-driving cars or robotic space exploration, this round-trip time is unacceptable. Edge AI eliminates this delay by enabling devices to make decisions instantly, right where the action is happening.
- Economics: Edge AI significantly reduces costs associated with connectivity and cloud infrastructure. By processing data on-device, it lowers or eliminates the expense of transmitting large data streams and the ongoing costs of maintaining cloud-based services. This makes many use cases, such as remote wildlife monitoring, far more feasible.
- Reliability: Systems that rely on a constant connection to the cloud are vulnerable to network outages. By moving intelligence to the edge, devices can continue to function even if their internet connection is lost. This is especially vital for mission-critical applications where safety is paramount, such as monitoring industrial machinery.
- Privacy: Edge AI protects user privacy by keeping sensitive data on the device. Instead of streaming raw video or audio to a remote server, a device can process the data locally to identify an event (like an intruder) and send only a notification. This reduces the risk of data breaches and is crucial for applications in sensitive fields like healthcare and security.
Components of Edge Computing
Edge computing operates through a layered architecture that processes data at various points from the device to the cloud. This ecosystem is composed of three main components, each with a distinct role. At a high level, this architecture explains where computation occurs and how data flows from the physical world to centralized analytics.
1. Edge Device
The Edge Device is the first point of data generation. These are the physical components, often embedded systems, that interact with the real world through sensors. They typically have limited processing power and memory. Examples: Sensors in a wind turbine, an IP security camera, a smart thermostat, or an industrial controller on a factory floor.
2. Edge Node/Gateway
The Edge Node or Gateway is the intermediate compute layer. It sits between the edge devices and the central cloud, aggregating, filtering, and processing data from multiple devices locally. This reduces the data volume sent upstream and provides faster response times. Examples: A small industrial PC, a dedicated server in a cell tower, or a consumer-grade device like a Raspberry Pi acting as a smart home hub.
3. Cloud Layer
The Cloud Layer is the centralized, remote computing network. It is used for tasks that don't require real-time processing and can handle massive data volumes. In an edge computing architecture, its role is for high-level analytics, long-term data storage, and the training of complex machine learning models that are then deployed back to the edge nodes. Examples: Large data centers run by providers like Amazon Web Services (AWS), Microsoft Azure, or Google Cloud.
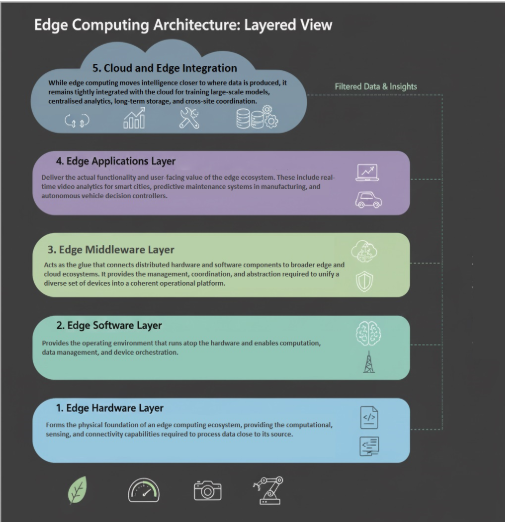
4. Edge Implementation Architecture
The below 5-layer architecture provides a deeper view of how edge systems are built internally, breaking the edge stack into hardware, software, middleware, applications, and cloud-integration layers. Both edge end nodes and edge gateways contain the same foundational layers of edge architecture, but end nodes implement lightweight, constrained versions while gateways provide a richer, more capable implementation designed for multi-device aggregation and advanced local intelligence.
Edge Computing Hardware
Edge hardware forms the physical foundation of an edge computing ecosystem, providing the computational, sensing, and connectivity capabilities required to process data close to its source. This includes IoT sensors, microcontrollers, embedded boards, edge gateways, accelerators, and ruggedised industrial devices placed in factories, hospitals, vehicles, or outdoor environments. These devices often integrate specialised hardware such as TPUs, NPUs, or lightweight GPUs to enable real-time machine learning, low-latency analytics, and intelligent decision-making at the edge. Energy efficiency, thermal constraints, and reliable connectivity are key considerations when selecting edge hardware, as these systems usually operate under strict power budgets and in diverse physical conditions. Together, these devices create a distributed network capable of capturing, pre-processing, and forwarding data without relying on continuous backhaul connectivity to the cloud.
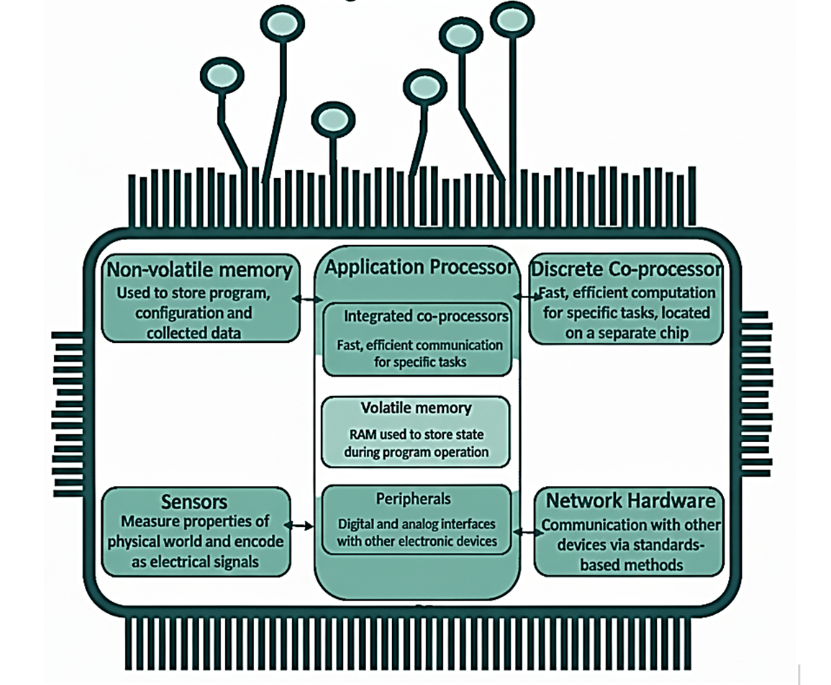
Fig: Edge Computing Hardware: A Component-Level View The diagram illustrates the core components typically found within an edge device or edge node, which are crucial for performing computation and processing data close to the source, rather than sending everything to a centralized cloud. This proximity is the essence of edge computing, enabling low-latency and real-time applications. The importance of this architecture lies in how these components work together to process and manage data locally: Sensors: These are the data generators. They measure properties of the physical world (e.g., temperature, pressure, images) and encode them as electrical signals. They are the starting point of the edge computing process. Non-volatile memory: This memory (like flash or SSD) is used to store the program, configuration, and collected data persistently, even when the power is off. It's where the operating system and application software reside. Application Processor: This is the device's central brain. It handles general-purpose tasks and often includes integrated co-processors for fast, efficient communication and specific tasks (like digital signal processing). Volatile memory (RAM): Used to store state during program operation. It's fast, temporary storage necessary for the processor to execute tasks efficiently. Discrete Co-processor: This is a separate, specialized chip used for fast, efficient computation for specific, demanding tasks, such as machine learning inference or complex encryption. Its separation allows the application processor to focus on general-purpose tasks. Peripherals: These are the interface components that manage digital and analog interfaces for connecting with other electronic devices (e.g., display drivers, I/O controllers). Network Hardware: This enables communication with other devices (including other edge nodes, the cloud, or central servers) via standards-based methods (like Wi-Fi, Ethernet, 5G). This is how data and processed insights are moved around the network.
Types of Edge devices:
Microcontrollers (MCUs) - The Foundation of Edge AI
Microcontrollers are small, inexpensive computing units that integrate a processor, memory, and peripheral interfaces on a single chip. They run firmware directly on bare metal and are designed for deterministic, low-power operation. Their simplicity and extremely low cost—combined with production volumes in the tens of billions—make them the backbone of embedded control systems. Although traditionally limited in resources, modern high-end MCUs increasingly support lightweight AI workloads. Examples:
- Atmel AVR (8-bit)
- Arm Cortex-M series
- Espressif ESP32 Common Uses:
Microcontrollers - Low-End Variants
Low-end MCUs prioritize minimal cost, tiny physical size, and very low energy consumption. They typically feature narrow data paths, modest memory, and limited clock frequencies. These devices are well suited for simple control tasks or periodic sensing but lack the computational capacity for most modern machine-learning workloads beyond trivial thresholding or event detection. Examples:
- 8-bit AVR MCUs
- PIC microcontrollers Common Uses:
- Thermostats
- simple gadgets
- instrumentation meters
- remote sensors
Microcontrollers - High-End Variants
High-end MCUs offer substantial improvements in performance, memory, and specialized instruction sets. With 32-bit architectures, optional floating-point units, and hundreds of MHz of clock speed, they can run more sophisticated signal-processing algorithms and lightweight AI models. They strike a practical balance between capability and power efficiency, making them a “sweet spot” for Edge AI. Examples:
- STM32H7 family
- Nordic nRF52840
- ESP32-S3 Common Uses:
- Smart appliances
- wearables
- higher-end IoT devices
- consumer electronics
Digital Signal Processors (DSPs)
DSPs are processors optimized for accelerating mathematical operations common in audio, vibration, and RF signal processing. Their architecture enables extremely fast multiply–accumulate operations and efficient execution of transforms such as FFTs. While not general-purpose compute platforms, they excel as dedicated engines for preprocessing or always-on AI tasks like keyword spotting. Examples:
- TI C55x/C66x DSPs
- Qualcomm Hexagon DSP Common Uses:
- Audio processing
- sensor preprocessing
- low-power keyword detection
Heterogeneous Compute
Modern edge devices often combine multiple compute elements—such as an MCU, a DSP, and a dedicated accelerator—to perform different tasks simultaneously. This division of labor allows low-power processors to run background tasks while more powerful units handle AI inference or high-rate signal processing. Examples:
Smart speaker chipsets combining low-power wake-word DSP + application processor Common Uses:
- Smart audio devices
- vision-enabled IoT devices
- robotics
System-on-Chip (SoC) Devices
SoCs integrate CPU cores, memory controllers, I/O, GPUs, and wireless radios into a compact chip capable of running full operating systems. Unlike MCUs, they support Linux or Android, enabling rich software stacks and high-level languages. They draw more power but deliver vastly higher computational capability, making them the workhorses of advanced Edge AI systems. Examples:
- Raspberry Pi (Broadcom SoC)
- Qualcomm Snapdragon
- Arm Cortex-A series Common Uses:
- Edge gateways
- multimedia devices
- robotics
- prototyping platforms
Deep Learning Accelerators (NPUs)
NPUs are specialized processors built to run neural networks efficiently. They accelerate matrix operations and parallel workloads central to deep learning. Depending on design, they may trade off flexibility for extreme efficiency or vice versa. They are commonly paired with MCUs or SoCs rather than used alone. Examples:
- Google Edge TPU
- NVIDIA Jetson NPU
- Syntiant NDP10x Common Uses:
- Real-time vision
- audio AI
- on-device classification and detection
FPGAs and ASICs
FPGAs allow developers to reconfigure hardware logic, making them powerful for prototyping or specialized accelerated workloads. ASICs, by contrast, implement fixed logic etched into silicon, achieving maximum efficiency and performance but at high engineering cost. Both are used when tight energy, latency, or throughput requirements cannot be met using general-purpose processors. Examples:
- Xilinx and Intel FPGAs
- Google Edge TPU ASIC Common Uses:
- High-performance embedded AI
- telecommunications
- defense systems
Development Boards & Production Ready Devices
Development boards expose the underlying processor, I/O, and interfaces, making them ideal for rapid prototyping and evaluation. Production-ready devices like industrial gateways package similar computing hardware in robust enclosures designed for deployment in real-world environments. Examples:
- Arduino Portenta
- Raspberry Pi
- NVIDIA Jetson Common Uses:
- Prototyping
- field pilots
- industrial IoT systems
Edge Servers/Gateway
Edge servers use conventional server-class hardware placed physically close to the deployment environment. They offer cloud-like compute power—sometimes with GPUs—while preserving the privacy and low latency benefits of local processing. They consume more energy but integrate well with existing IT infrastructure. Examples:
- Industrial edge servers
- GPU-enabled microservers Common Uses:
- Factory automation
- smart buildings
- real-time analytics at the network edge
Multi-Device Architectures
Edge AI deployments often involve networks of devices that collaborate. Simple sensors collect data, a gateway performs complex processing, and edge servers or the cloud handle further aggregation. This division supports scalability, energy efficiency, and privacy. Examples:
Sensor networks feeding an edge gateway for AI processing Common Uses:
- Large-scale monitoring systems
- distributed sensing
- industrial IoT
Edge Software:
Edge software provides the operating environment that runs atop the hardware and enables computation, data management, and device orchestration. This includes lightweight operating systems such as Linux variants, real-time operating systems (RTOS) for time-critical applications, container runtimes optimised for constrained environments, and embedded ML libraries such as TensorFlow Lite, Edge Impulse runtimes, or ONNX Runtime Mobile. Edge software also covers firmware, networking stacks, security modules, and local databases that support data retention, encryption, and efficient storage. A critical role of edge software is ensuring that devices can autonomously run AI models, filter data, and communicate intelligently based on context. This layer bridges the gap between hardware limitations and application demands, enabling real-time performance while maintaining reliability under resource constraints. Software on the edge sits above the middleware and focuses on management, connectivity, security, and local data processing.
Key categories:
Device Management
- Onboarding, provisioning, identity management
- Firmware updates (OTA)
- Health checks
Data Collection & Preprocessing
- Sampling, filtering, compression
- Local feature extraction -Running TinyML models
Networking & Connectivity
- MQTT / CoAP / HTTP
- Edge-to-edge and edge-to-cloud messaging
- Network resiliency handling
Security Services
- Local encryption
- Secure data paths
- Access control
Remote Monitoring & Configuration
- Logs, metrics, events
- Control signals
- System telemetry
A note on dependencies and complexity of hardware and software in edge world:
-
Complexity of Edge Software Stacks: Before going into the next layer, it is important to understand the hardware and software complexity of edge systems. Modern software typically has a lot of dependencies, and AI development takes this to the next level. Data science and machine learning tools often require absurd numbers of additional third-party libraries; installing a major deep learning framework such as TensorFlow brings everything from web servers to databases along for the ride leading to dependency chaos.
-
Embedded Systems and Their Heavy Computational Dependencies: Things can get complex on the embedded side, too, since signal processing and machine learning algorithms commonly require sophisticated, highly optimized mathematical computing libraries. In addition, the compilation and deployment of embedded C++ code often requires a rat’s nest of dependencies to be present on a machine.
-
Managing Dependencies in Edge AI: All of these dependencies can be an absolute nightmare and managing them is truly one of the most challenging parts of edge AI development. Various techniques exist to make it easier, from containerization to language-specific environment management. For Python, one of the most helpful tools is called Poetry. It aims to simplify the process of specifying, installing, and isolating dependencies in multiple environments on a single machine. Other essential tools include OS-specific package management systems like aptitude (Debian GNU/Linux) and Homebrew (macOS). One of the worst parts of dependency management comes when attempting to integrate different parts of a system together. For example, a model trained with one version of a deep learning framework may not be compatible with an inferencing framework released slightly later. This makes it extremely important to test systems end to end very early in the development process, to avoid nasty surprises later on.
Virtualization and Isolation
To solve this dependency chaos, resource management, and security concerns, the industry relies on isolation technologies, primarily Virtual Machines (VMs) and Containers.
Virtual Machines (VMs)
A Virtual Machine (VM) is an emulation of a physical computer system. It provides a complete, isolated environment that behaves exactly like a standalone physical machine, but it exists purely as software on top of actual hardware. VMs provide full OS isolation (via hypervisors), allowing an edge server or gateway to run multiple, completely separate operating systems (e.g., Windows for a legacy app, Linux for a new AI service) simultaneously. They offer strongest security and isolation, however, there is a high resource overhead (CPU, RAM, disk space) due to running a full OS kernel for each VM. VMs are typically limited to more powerful Edge Servers/Gateways.
Key Components: Virtual Machine (VM) : This represents a single, self-contained virtual computer.
- Guest OS (Full Operating System): Each VM runs its own, entirely separate operating system (e.g., Windows, Linux, Ubuntu, macOS). This includes its own kernel, system libraries, and drivers.
- User Applications: Just like on a physical computer, applications (e.g., data analysis tools, AI models, web servers) run within the Guest OS.
- Virtual Hardware / Drivers: To the Guest OS, it appears as though it's interacting with dedicated hardware components (e.g., virtual CPUs (vCPU), virtual disks (vDisk), virtual network interface cards (vNIC)). These are software abstractions of the physical hardware.
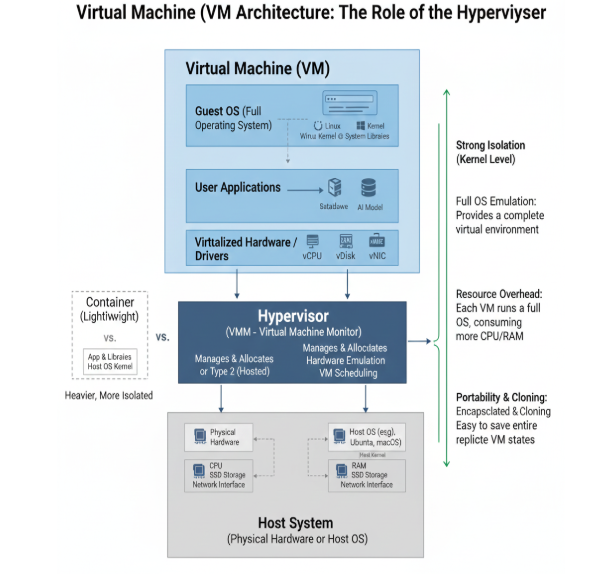
What is a Hypervisor?
The Hypervisor (also known as a Virtual Machine Monitor or VMM) is the fundamental software layer that makes virtualization possible. It sits between the VMs and the physical hardware, responsible for:
- Managing & Allocating Resources: The Hypervisor manages and allocates the underlying physical resources (CPU, RAM, storage, network) to each of the running VMs. It ensures that VMs can share the physical hardware without interfering with each other.
- Hardware Emulation: It creates and manages the "virtual hardware" that each Guest OS sees.
- VM Scheduling: It schedules when each VM gets access to the physical CPU, ensuring fair access and performance.
How VMs Provide Isolation
VMs provide strong isolation at the kernel level:
- Each VM is completely independent; a crash in one VM will not affect others.
- They are sandboxed from each other and from the host system's applications.
Why VMs are Used (and their Trade-offs)
- Strong Isolation (Kernel Level): This is a primary benefit. VMs offer the highest degree of separation, making them excellent for security-critical applications or running incompatible operating systems on the same physical hardware.
- Full OS Emulation: Each VM provides a complete virtual environment, allowing it to run any software designed for its Guest OS, exactly as it would on physical hardware.
- Resource Overhead: The main drawback is significant resource consumption. Because each VM has its own full Guest OS (including its own kernel), it requires a substantial amount of CPU, RAM, and disk space. This "heaviness" makes them less suitable for highly resource-constrained edge devices.
- Portability & Cloning: VMs are highly portable. An entire VM can be encapsulated into a single file, making it easy to move, clone, or back up.
Containers and Microservices (Critical for Edge AI)
Containers provide lightweight isolation by bundling application code, configuration, and all its dependencies into a single, portable package that shares the host device's operating system kernel. They solve the biggest pain in edge AI: dependency chaos. Different toolchains (e.g., Python ML and C++ embedded code) can coexist safely. They are low overhead, fast startup, high portability across heterogeneous edge devices. Ideal for microservices and "swarm" architectures. Tools that support containerisation are Docker (for building/testing), and Kubernetes variants like K3s or MicroK8s (for managing large fleets
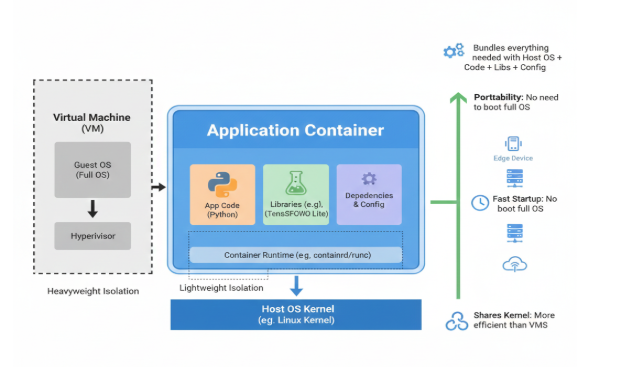
At its core, a container is a standardized, lightweight, and portable software package that includes everything needed to run a piece of software: the application code, its runtime, libraries, and system tools, all isolated from the host system. Key Characteristics:
- Application Container (Blue Box): This represents a single, self-contained unit.
- App Code (e.g., Python): Your actual application logic resides here.
- Libraries (e.g., TensorFlow Lite): All the necessary software libraries and frameworks your application depends on are bundled inside.
- Dependencies & Config: Any other system tools, configurations, or settings required for the application to run correctly are also included.
- Container Runtime (e.g., containerd/runc): This is a small piece of software on the host that manages the lifecycle of containers (starting, stopping, pausing). It acts as the interface between the container and the host OS kernel.
- Host OS Kernel (e.g., Linux Kernel): This is the heart of the operating system running on the physical hardware (your edge device). Crucially, containers share this single host OS kernel.
How Containers Provide Isolation
Containers achieve isolation by leveraging features of the host operating system kernel to create an isolated environment for each application. This means:
- Each container thinks it has its own filesystem, network interfaces, and process space.
- But they all run on the same kernel as the host.
Why Containers are Critical for Edge Computing
The key benefits that make containers ideal for edge environments are:
- Bundles Everything Needed: This solves the "dependency chaos" problem. By including all code, libraries, and configurations, a container guarantees that an application will run consistently, regardless of the underlying host environment.
- Portability: Because everything is bundled, a container can be moved and run on any compatible edge device (or cloud server) without needing to reconfigure the host OS or reinstall dependencies. There's no need to "boot a full OS" within the container.
- Fast Startup: Since containers don't need to boot an entire guest operating system, they start up almost instantly, which is vital for real-time responses at the edge.
- Shares Kernel: More Efficient than VMs: This is the most significant differentiator. By sharing the host OS kernel, containers consume significantly fewer resources (CPU, RAM) than VMs, making them suitable for resource-constrained edge devices.
Microservices
Microservices provide an architectural style where a single large application (a monolith) is structured as a collection of smaller, independent services. Each service is self-contained and implements a specific business capability (e.g., "Payment Processing," "User Authentication"). Containers are the essential delivery vehicle for microservices. Microservices communicate over lightweight mechanisms (like APIs/HTTP) and can be developed, deployed, and scaled independently. The architectural principles of microservices—isolation, rapid scaling, and independent deployment—are extremely difficult and costly to achieve using heavy Virtual Machines. Containers provide the perfect, lightweight packaging and consistent runtime environment needed to deploy and manage hundreds or thousands of small, modular services efficiently. Orchestration platforms like Kubernetes manage these containers at scale, making the microservices architecture viable for large enterprises
Container vs. Virtual Machine (VM) - The Key Difference
VMs (Heavyweight Isolation): A VM includes a Guest OS (Full OS), which means it has its own dedicated kernel and all the necessary system files. This Guest OS runs on top of a Hypervisor, which then interfaces with the physical hardware. Difference: VMs provide stronger isolation (hardware-level virtualization) but come with substantial overhead because each VM duplicates a full operating system. Containers, on the other hand, provide lightweight, OS-level isolation by sharing the host kernel, making them far more efficient for edge deployments where resources are precious. In essence, containers are the workhorses of modern, scalable edge AI deployments, providing the flexibility and efficiency needed to run complex applications on diverse and often resource-limited edge hardware.
Edge Middleware
Edge Middleware serves as the runtime substrate and management "glue" that binds the distributed Edge Hardware and Software components into a single, cohesive operational platform. Sitting above the foundational software, its primary role is to abstract complexity, manage dependencies, and orchestrate the deployment and lifecycle of applications across a diverse fleet of edge nodes. It provides the management, coordination, and abstraction required to unify a diverse set of devices into a coherent operational platform. Examples include Kubernetes variants such as K3s or MicroK8s, IoT orchestration frameworks like Azure IoT Edge or AWS Greengrass, and open-source tools such as EdgeX Foundry. Middleware supports device provisioning, data pipelines, model deployment, remote configuration, and security policy enforcement. It ensures that developers and operators can deploy applications consistently, update ML models remotely, manage multi-device workloads, and monitor performance across thousands of heterogeneous edge nodes. By hiding low-level hardware complexity and providing shared services such as messaging, authentication, and workload balancing, middleware enables scalable and maintainable edge architectures. Middleware is responsible for:
- Workload Orchestration: It is responsible for model deployment and application placement, ensuring that ML models and containerized workloads are consistently and remotely updated and run on the correct edge devices.
- Abstraction and Interoperability: It hides low-level hardware variations and provides unified APIs, allowing developers to focus on application logic rather than managing differing protocols (like Modbus or MQTT) or hardware specifications.
- Security and Management: Middleware enforces security policies, manages device provisioning, and facilitates remote configuration and monitoring across thousands of heterogeneous nodes. By leveraging isolation tools provided by the Edge Software layer, Middleware enables scalable, maintainable, and reliable hybrid edge architectures.
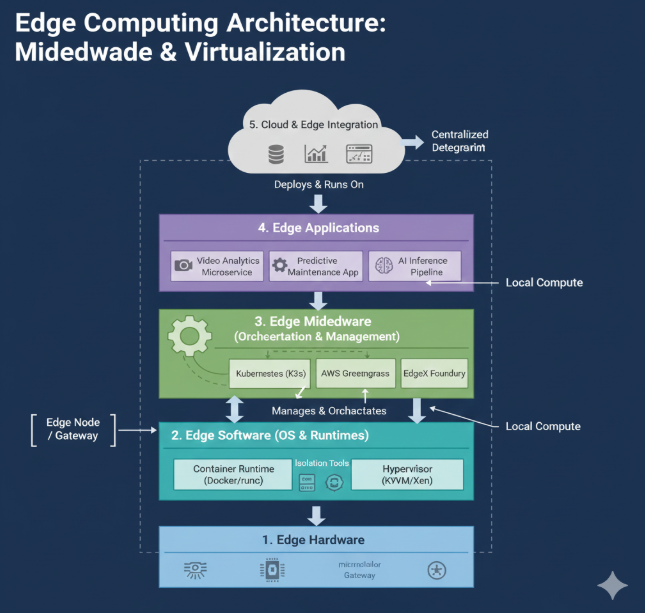
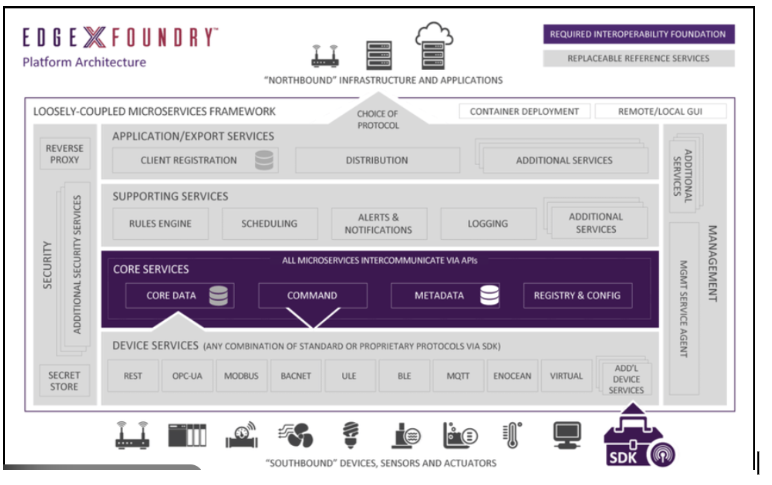
Common Edge Middleware Examples: Several major edge middleware platforms exist today, including:
- EdgeX Foundry
- KubeEdge
- AWS IoT Greengrass
- Azure IoT Edge
- Open Horizon
EdgeX Foundry:
Among these, EdgeX Foundry stands out because it is completely vendor-neutral and composed entirely of independent microservices packaged as containers. This gives it exceptional modularity, letting developers replace, scale, or customize any microservice without affecting others. Example: Modern warehouses store:
- Food and pharmaceuticals
- Electronics and precision components
- Perishables and climate-sensitive products These items require strict environmental control, particularly temperature.
Warehouses often need to monitor:
- Dozens to thousands of temperature sensors
- Multiple zones or storage rooms
- Rapid changes (e.g., freezer door left open)
- Compliance with regulations (FDA, GMP, cold-chain standards)
A common critical threshold (used in your figure) is 25 °C, though exact limits vary by product. If temperature exceeds the threshold:
- Inventory may be damaged
- Safety compliance may be violated
- Financial loss may occur
- Regulatory issues may arise This makes real-time alerts absolutely essential.
Challenges With Traditional (Cloud-Only) Monitoring
Sending all raw sensor data to the cloud introduces several problems:
- Bandwidth Overload: Hundreds of sensors sending data every second quickly saturate the network.
- Latency: Cloud round-trips can be slow, leading to delayed warnings.
- Connectivity Risk: If the internet connection drops, monitoring stops entirely.
- Cost: Cloud ingestion, processing, and storage become expensive at scale.
- Lack of Local Autonomy: Critical alerts can’t be generated locally without cloud access.
This is where edge middleware—such as EdgeX Foundry—solves the problem by placing intelligence closer to the data source.
EdgeX based implementation:
This is where EdgeX Foundry’s edge-oriented, microservice-driven design becomes essential. Instead of sending raw data to the cloud, local EdgeX microservices—running in Docker containers on an edge gateway—handle ingestion, storage, rule evaluation, and event generation right where the data originates. A device service collects temperature readings, Core Data stores them locally, and the Rules Engine evaluates them in real time. If the temperature crosses the threshold, the system triggers an alert immediately. Only meaningful events, not continuous raw streams, travel to the cloud.

Implementation:
Device Service
This is the first point of contact between the physical hardware and the EdgeX ecosystem. It would:
- Connect to temperature sensors, vibration sensors, humidity sensors, or any maintenance-related device.
- Convert raw sensor readings into a standard EdgeX format.
- Push those readings into the system in a consistent way, regardless of the hardware vendor.
This microservice shields the rest of the system from hardware complexity.
Core Data
Once the Device Service collects sensor readings, Core Data stores them locally on the edge. It enables:
- Buffering data even if cloud connectivity is down
- Reliable, timestamped records of environmental or equipment-health metrics
- Consistent data delivery to downstream microservices
This is essential for maintenance audit trails and historical inspection.
Metadata
For a scalable warehouse deployment, Metadata keeps track of:
- All registered devices
- Their operating parameters
- Their relationships (zones, racks, machines)
- Maintenance-related configurations (thresholds, alert conditions)
This microservice ensures the system knows which device is reporting what, and where it physically is.
Rules Engine
This is the intelligence layer for maintenance automation. It continuously evaluates incoming data from Core Data and applies logic such as:
- “If temperature > 25°C, trigger alert.”
- “If vibration exceeds baseline for 10 seconds, signal possible motor failure.”
- “If humidity drifts outside tolerance, notify maintenance staff.”
The Rules Engine is what transforms sensor readings into actionable insights.
Notifications & Alerts Service
When the Rules Engine detects a problem, this microservice handles messaging. It can:
- Send alerts to dashboards
- Trigger SMS, email, or integration with work-order systems
- Prioritize and classify alerts based on severity
For maintenance teams, this is the practical touchpoint—the moment a problem is flagged.
App Services (Application Services)
These microservices prepare, filter, or enrich data before sending it out. For maintenance, App Services might:
- Format alerts for the cloud dashboard
- Forward anomaly events to a maintenance platform
- Route data to predictive-maintenance AI running in the cloud
They enable the system to connect edge insights to enterprise systems.
Export Client / Cloud Connector
This microservice makes sure critical events reach the cloud. For maintenance workflows, it would:
- Avoid sending raw data, saving bandwidth
- Maintain secure, efficient communication between edge and cloud
It ensures cloud systems receive only the information they need.
Edge Applications
Edge applications deliver the actual functionality and user-facing value of the edge ecosystem. These include real-time video analytics for smart cities, predictive maintenance systems in manufacturing, gesture recognition for teleoperation, medical monitoring apps in hospitals, and autonomous vehicle decision controllers. Edge applications leverage local processing to provide ultra-low latency responses, enhance privacy by keeping sensitive data onsite, and enable offline or intermittently connected operation. Many applications follow event-driven or AI-driven patterns where insights must be computed instantly to trigger local actions such as alerts, control signals, or robotic movements. They are often deployed as microservices, ML inference pipelines, or containerised workloads orchestrated through middleware. Edge applications represent the culmination of the hardware, software, and middleware stack, unlocking capabilities that are not possible with cloud-only systems. Applications consume middleware services and edge software capabilities to deliver meaningful functionality.
Typical Edge AI Applications
- Vision analytics (e.g., defect detection, occupancy detection)
- Predictive maintenance
- Gesture recognition / pose estimation
- Audio intelligence (keyword spotting, anomaly detection)
- Robotics perception + control loops
- Industrial automation workflows
These applications run:
- Fully on the edge (no cloud)
- Partially on the edge (hybrid)
- Using collaborative multi-device architectures
Cloud and Edge Integration
While edge computing moves intelligence closer to where data is produced, it remains tightly integrated with the cloud for training large-scale models, centralised analytics, long-term storage, and cross-site coordination. Cloud systems provide high-performance computing resources for developing and updating ML models, which are later deployed to the edge for inference. They also aggregate data from many edge nodes to provide global views, dashboards, or multi-location optimisation strategies. Hybrid architectures allow tasks to be dynamically split between the edge and cloud based on latency, bandwidth, and energy constraints. This integration ensures that edge deployments benefit from both local autonomy and cloud-scale intelligence, forming a complete end-to-end ecosystem. While the edge handles real-time tasks, the cloud manages:
- Model training, versioning, rollout
- Fleet management for thousands of devices
- Global analytics
- Digital twins
- Data storage & archiving
- Remote diagnostics
The cloud and edge cooperate to achieve:
- Low latency
- High reliability
- Better privacy/security
- Reduced bandwidth usage
Challenges in Edge Computing
While edge computing offers significant benefits, deploying and managing it at scale presents a unique set of challenges.
- Device Heterogeneity: The edge ecosystem is composed of a vast and diverse range of devices, from simple sensors to powerful industrial computers as noted above. These devices run on different hardware architectures, operating systems, and communication protocols. This lack of standardization makes it incredibly difficult to create a single software solution that can be deployed across a heterogeneous environment.
- Scalability: A typical cloud system scales by adding more servers to a centralized data center, but edge computing involves deploying and managing thousands or even millions of devices distributed across vast geographical areas. Managing this dispersed network, ensuring consistent performance, and handling the sheer volume of devices is a massive logistical and technical challenge.
- Remote Management and Updates: Edge devices are often located in remote, difficult-to-access, or unsecured environments. This makes it challenging to perform manual maintenance, push software updates, or troubleshoot issues. If a device fails or is compromised, remote management is the only viable option for ensuring system reliability and security.
- Security: The distributed nature of the edge network increases the attack surface. Unlike a secure, centralized cloud data center, edge devices are physically exposed and often have limited built-in security. They are more vulnerable to physical tampering, network attacks, and data breaches, making secure communication and data protection a primary concern.
- Resource Constraints: Many edge devices, especially small, battery-powered sensors, have severe limitations in terms of compute power, memory, and energy. This makes it impossible to run the same complex software or robust security protocols as a cloud server, requiring developers to create highly efficient and lightweight applications.
BLERP Analysis of the EdgeX Foundry Warehouse Monitoring Example
-
B — Bandwidth: EdgeX Foundry dramatically reduces bandwidth consumption compared to a cloud-only design.
- Raw sensor data (e.g., hundreds of temperature readings per second) is processed locally, not streamed to the cloud.
- Only alerts, summaries, or filtered events are sent upstream.
- Export Services support light-weight, event-driven messages instead of continuous data pipelines.
- Impact:
- Bandwidth reduction typically exceeds 90–99%, especially in sensor-dense warehouses.
- Systems remain stable even in low-connectivity environments or bandwidth-restricted facilities.
-
L — Latency: EdgeX optimizes end-to-end response time by performing computation at the edge.
- The Rules Engine evaluates data on the same device that collects it.
- Alerts (e.g., “temp > 25°C”) trigger instantly without waiting for cloud round trips.
- Critical action (e.g., shutting down cooling systems or notifying staff) happens near-zero delay.
- Impact:
- Typical alert latency drops to tens of milliseconds rather than seconds.
- Suitable for safety-critical environments where rapid response is mandatory.
-
E — Economics: EdgeX lowers operational costs and improves long-term financial feasibility. Cost Savings Come From:
- Lower cloud compute and storage because raw data isn’t streamed constantly.
- Reduced network infrastructure costs — no need for costly high-throughput links.
- Modular microservices reduce maintenance overhead and allow selective scaling.
- Open-source foundation eliminates licensing fees.
- Impact:
- Total cost of ownership (TCO) declines significantly for large deployments.
- Economically viable to scale from dozens to thousands of sensors.
-
R — Reliability: EdgeX enhances system robustness by enabling independent, fault-tolerant components.
- Microservices operate independently — failure in one does not collapse the system.
- Local processing ensures continuous operation even if:
- Cloud connection is down
- Network is unstable
- Remote services fail
- Containers allow fast restarts and predictable behavior.
- Impact:
- High operational availability (often >99% uptime).
- Critical warehouse alerts continue even during outages — ideal for cold-chain and high-value goods.
-
P — Privacy: EdgeX strengthens privacy by keeping sensitive sensor data local.
- Raw data stays on edge gateways unless explicitly exported.
- Only processed, minimal, or anonymized data needs to reach the cloud.
- Containers help isolate services, reducing attack surface.
- Supports encrypted communication and secure secret storage.
- Impact:
- Lower exposure of internal warehouse activity patterns.
- Better compliance with data sovereignty or audit requirements.
- Safer integration with third-party cloud dashboards.