
Lecture 4 - Part 1
Contents
Introduction to Detection
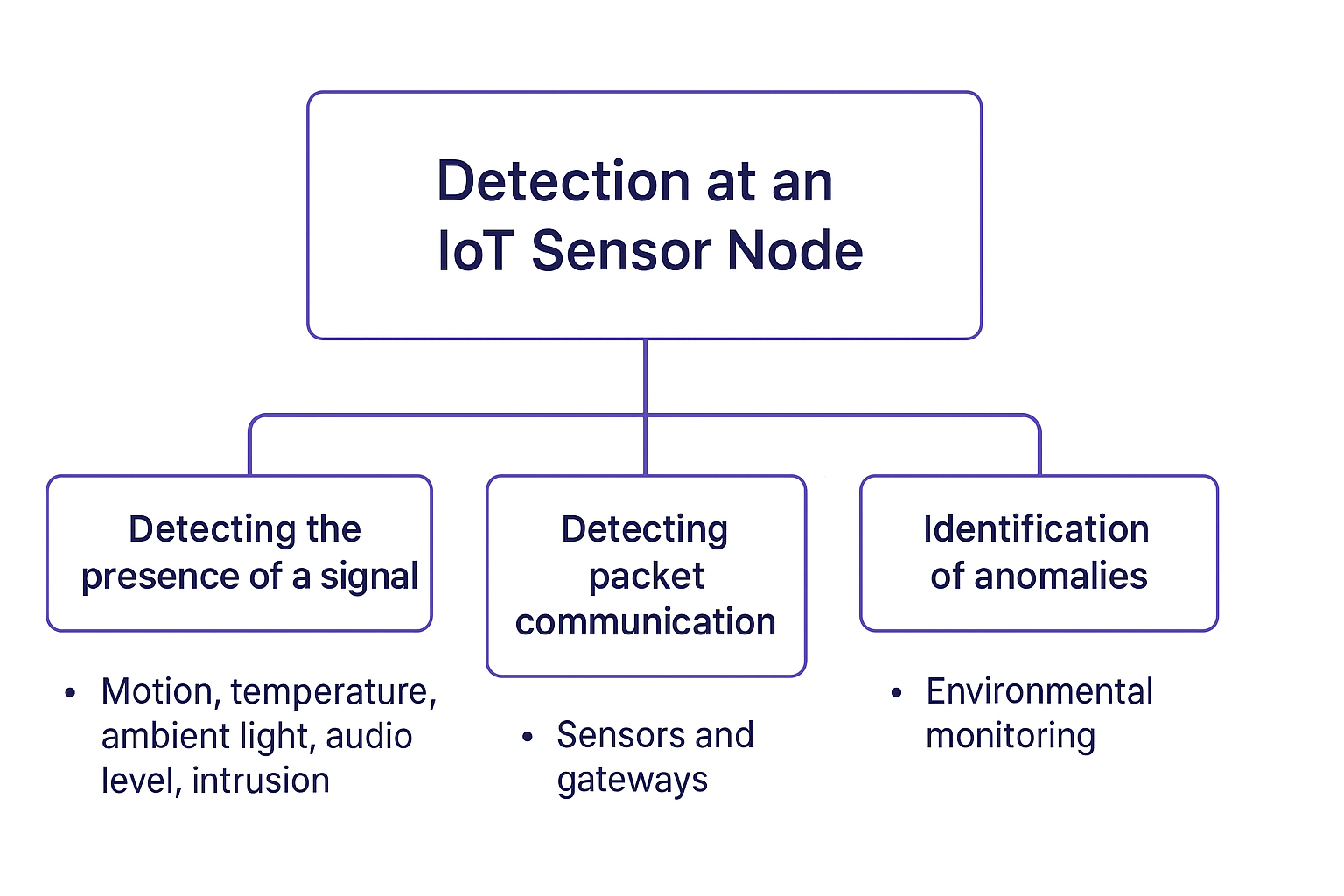
One of the key functionality at the IoT sensor node is to detect an event. The sensing tasks range from:
- Detecting the motion, change in temperature, ambient light, intrusion or change in audio level. All these tasks are detecting the absence or presence of certain signal.
- Detecting the packets sent to communicate these readings between a sensor and the gateway. In other words, we often need to detect the packets and then decode it to understand the values.
- Identification of anomalies, e.g. in the environmental monitoring case (increase in CO, particulate matter levels etc.).
Detection of certain attributes also is key in triggering more complex processing operation. For instance, consider an audio IoT sensors deployed at scale in wild. These are deployed to detect presence of certain species of birds or animals [1]. Rather than capturing the sound and processing it continuously, often in the IoT systems (typically having multiple cores of MCUs), its customary to detect the sound first and then trigger the complex classification pipeline. This saves the unnecessary usage of battery on the sensors, increasing the operational life-time for the deployment.
A detection problem can be casted as a simple hypothesis testing problem. Under each hypothesis, the desired attribute follows a completely known distribution. The classical approach for the detection theory are based on Neyman-Pearson theorem and a Bayesian approach is based on Bayesian Risk Minimisation. When the distribution of the signal is not exactly known then energy detection can be employed. We will only explore these aspects alongside some representative use-cases where these will be employed in IoT deployments.
Neyman-Pearson Criterion
To appreciate Neyman-Pearson criterion, let us start with a very simple example of binary hypothesis testing. In other words, let us assume that we observe a single realisation (sample/instance) of a random variable whose PDF is either or . Essentially, the hypothesis testing problem is to determine from single sample say whether or , i.e. which distribution it belongs to. Mathematically,
where is referred to as the null hypothesis and as the alternate hypothesis. The PDF under both hypothesis is shown below, with the difference in accounting for the shift to the right under . As you can see from the single sample it is difficult to detect which one of the distributions it belongs to specially given the overlap between them. The decision can be made on basis of fixed threshold. The threshold line is indicated by dashed black line. Drag the slider at the bottom of the figure to fix the threshold to .
This presents one possible approach, i.e., if then its more likely for , therefore hypothesis is true. Alternatively, we can say if then . So the detection model is simply comparing the observed with a threshold, i.e., say . With this approach we can make two type of errors:
- If we decide instead of , we make Type I error. The probability of making Type I error, i.e., say is known as Probability of False Alarm and is denoted by .
- If we decide instead of , we make Type II error. The probability of making Type II error, i.e., say is known as Probability of Missed Detection and is denoted by . The probability of missed detection is .
As you will notice from the figure above, it is not possible to reduce both error probabilities simultaneously. Reducing one increases the other, i.e., there is inherent trade-off between and . Consequently, a sensible approach to designing optimal detector is to hold one of these probabilities constant while minimising the other. For instance, fix , with being small constant while minimising the .
Definition
The approach of selecting optimal detector which minimises the probability of missed-detection or equally maximises the probability of detection, while keeping the probability of the false-alarm constant is known as Neyman-Pearson theorem. In other words, The Neyman–Pearson test chooses the threshold such that the false alarm probability is exactly . This ensures that among all tests with false alarm probability , the likelihood ratio test achieves the highest probability of detection. In other words, to maximise the for given deicide if:
where, is the observation vector, the threshold is found from
What the formula says is given is the likelihood ratio:
- If it’s larger than the threshold , we decide (signal present).
- Otherwise, we decide (signal absent).
The threshold is not arbitrary—it is chosen so that the probability of false alarm equals a predefined level . Lastly, the
This integral means: we add up the probability mass of all outcomes that would make us mistakenly decide , when is in fact true. That probability must equal , which is a design parameter (for example, ).
Binary Hypothesis test
For the hypothesis test of the problem we introduced above, we can easily find the NP test. Assume that we require . Then, from we decide if
or
or finally
At this point we could determine from the false alarm constraint
A simpler approach is to take logarithms (since log is monotonic). So we decide if
Letting , we decide if . To explicitly find we use the constraint:
Thus . The NP test is to decide if . The detection probability is then
If instead we require , then the threshold is found from
which gives . Then
This essentially shows that you can trade the higher for tolerating higher .
General Problem Setup for Detection of DC Buried in Noise
Consider the binary hypothesis testing problem:
where:
- is the observed signal at time
- is a known constant amplitude
- is additive white Gaussian noise
For observations , the hypotheses become:
where and .
Likelihood Functions
Under each hypothesis, the likelihood functions are:
Likelihood Ratio Test (LRT)
The likelihood ratio is:
Taking the natural logarithm:
The LRT decision rule is:
This simplifies to the test statistic:
where .
Neyman-Pearson Criterion
The Neyman-Pearson lemma states that for a given probability of false alarm , the likelihood ratio test maximizes the probability of detection (or equivalently, minimizes the probability of missed detection).
For our problem:
- Under :
- Under :
The probability of false alarm is:
The probability of detection is:
where is the Q-function (complement of the standard normal CDF). The value is often known as Energy-to-noise-ratio (can be expresed in dB scale as ). The figure below studies impact of varying ENR on for various 's.
Receiver Operating Curve (ROC)
A Receiver Operating Characteristic (ROC) curve is a graphical tool used to evaluate the performance of a binary classifier system by illustrating the trade-off between and across different decision thresholds. Each point on the curve corresponds to a particular threshold, showing how increasing sensitivity (detecting more true positives) often comes at the cost of increased false alarms. The ROC curve provides a comprehensive view of a system’s discriminative ability, with curves closer to the top-left corner indicating better performance. The diagonal line represents random guessing.
Generalization: Bayes Risk
The Neyman-Pearson approach fixes and maximizes . A more general approach is to minimize the Bayes risk, which considers the costs of different decision outcomes and prior probabilities.
Bayes Risk Formulation
Let:
- = cost of deciding when is true
- , = prior probabilities
The average risk is:
Typically, we assume (correct decisions have no cost), so:
where is the probability of missed detection.
Bayes Decision Rule
The Bayes optimal decision rule minimizes the expected risk:
This shows that the optimal threshold depends on:
- The cost ratio
- The prior probability ratio
Special Cases
Equal costs and priors: , Threshold = 1 (decide based on which hypothesis is more likely)
Minimax criterion: Choose the threshold to minimize the maximum possible risk
Neyman-Pearson: Equivalent to Bayes with specific cost assignments
The Bayes framework provides a unified approach that encompasses the Neyman-Pearson criterion as a special case, while allowing for incorporation of prior knowledge and decision costs.
References
[1] Pringle, S., Dallimer, M., Goddard, M.A. et al. Opportunities and challenges for monitoring terrestrial biodiversity in the robotics age. Nat Ecol Evol 9, 1031–1042 (2025). https://doi.org/10.1038/s41559-025-02704-9
[2] Kay, Steven M. Fundamentals of statistical signal processing: Detection theory. Prentice-Hall, Inc., 1993.